Appears in Proceedings of the 10th ACM Conference on Computer and Communications Security (CCS'03), October 27-30, 2003, Washington, DC, USA. For printable versions of this paper (Postscript, PDF), and presentation slides, see https://www.csa.iisc.ac.in/~vg/papers/ccs2003
Vinod Ganapathy, Somesh Jha
University of Wisconsin-Madison
David Chandler, David Melski, David Vitek
Grammatech Inc., Ithaca, NY 14850
This paper addresses the issue of identifying buffer overrun vulnerabilities by statically analyzing C source code. We demonstrate a light-weight analysis based on modeling C string manipulations as a linear program. We also present fast, scalable solvers based on linear programming, and demonstrate techniques to make the program analysis context sensitive. Based on these techniques, we built a prototype and used it to identify several vulnerabilities in popular security critical applications.
D.3.3Language Constructs and FeaturesConstraints G.1.6OptimizationLinear Programming D.2.5Software EngineeringTesting and Debugging
Algorithms, Languages, Reliability, Security
Buffer overruns are one of the most exploited class of security vulnerabilities. In a study by the SANS institute [3], buffer overruns in RPC services ranked as the top vulnerability to UNIX systems. A simple mistake on the part of a careless programmer can cause a serious security problem with consequences as serious as a remote user acquiring root privileges on the vulnerable machine. To add to the problem, these vulnerabilities are easy to exploit, and ``cookbooks'' [4] are available to construct such exploits. As observed by several researchers [22,30], C is highly vulnerable because there are several library functions that manipulate buffers in an unsafe way.
Several approaches have been proposed to mitigate the problem: these range from dynamic techniques [8,10,11,13,18,24] that prevent attacks based on buffer overruns, to static techniques [17,22,26,29,30] that examine source code to eliminate these bugs before the code is deployed. Unlike static techniques, dynamic techniques do not eliminate bugs, and typically have the undesirable effect of causing the application to crash when an attack is discovered.
In this paper, we describe the design and implementation of a tool that
statically analyzes C source code to detect buffer overrun vulnerabilities.
In particular, this paper demonstrates:
![]() The use of static analysis to model C string manipulations as a
linear program.
The use of static analysis to model C string manipulations as a
linear program.
![]() The design and implementation of fast, scalable solvers based on
novel use of techniques from the linear programming literature. The
solution to the linear program determines buffer bounds.
The design and implementation of fast, scalable solvers based on
novel use of techniques from the linear programming literature. The
solution to the linear program determines buffer bounds.
![]() Techniques to make the program analysis context sensitive.
Techniques to make the program analysis context sensitive.
![]() The efficacy of other program analysis techniques, such as static slicing
to understand and eliminate bugs from source code.
The efficacy of other program analysis techniques, such as static slicing
to understand and eliminate bugs from source code.
One of our principle design goals was to make the tool scale to large real
world applications. We used the tool to audit several popular and commercially
used packages. The tool identified ![]() previously unknown buffer overruns in
wu-ftpd-2.6.2 (Section 6.1.1) in addition
to several known vulnerabilities in other applications.
previously unknown buffer overruns in
wu-ftpd-2.6.2 (Section 6.1.1) in addition
to several known vulnerabilities in other applications.
The rest of the paper is laid out as follows: We discuss related research in Section 2, followed by an overall description of our tool in Section 3. Section 4 describes constraint resolution techniques used by our tool, and Section 5 describes techniques to make the program analysis context-sensitive. Section 6 contains experimental results, and Section 7 concludes.
This paper focuses on static analysis techniques that examine source code for the presence of buffer overruns, and thus help the developer in eliminating the overrun before source code is deployed. Several static analysis tools have been proposed. These tools can be broadly classified as (a) Annotation driven tools (b) Tools that use symbolic analysis and (c) Tools that extract a model from the source code, and use it to detect the presence of bugs.
CSSV [17] and Splint [22] are
annotation driven tools. In these tools, user-supplied annotations, such as
pre- and post-conditions of a function, are used to aid static analysis. CSSV
aims to find all buffer overflows with just a few false alarms. The basic idea
is to convert the C program into an integer program, with correctness
assertions included, and use a conservative static analysis algorithm to detect
faulty integer manipulations, which directly translate to bugs in the C source
code. The analysis is performed on a per-procedure basis, and annotations
(called contracts) are used to make the analysis inter-procedural. The
number of false alarms generated by the tool depends on the accuracy of the
contracts. The analysis used by CSSV to check the correctness of integer
manipulations was heavyweight, and may scale poorly to large programs. For
instance, CSSV took ![]() seconds to analyze a string manipulation program
with a total of about
seconds to analyze a string manipulation program
with a total of about ![]() lines of code. Splint on the other hand, sacrifices
soundness and completeness, and uses a light-weight static analysis to detect
bugs in source code. Splint uses a flow-sensitive intra-procedural program
analysis, and user supplied pre- and post-conditions are used to make the
analysis inter-procedural.
lines of code. Splint on the other hand, sacrifices
soundness and completeness, and uses a light-weight static analysis to detect
bugs in source code. Splint uses a flow-sensitive intra-procedural program
analysis, and user supplied pre- and post-conditions are used to make the
analysis inter-procedural.
ARCHER [33] is a tool that functions by symbolically executing the code, while maintaining information about variables in a database as execution proceeds. The current state of the program is given by the values in the database. The execution of program statements potentially causes a change in the state of the program. At statements that access buffers, ARCHER checks, using the database, whether the access is within the bounds of the array, and flags an error if not. Rugina and Rinard [26] describe a tool geared specifically to detect out-of-bounds errors and race conditions on small divide and conquer programs where they determine symbolic bounds on array indices and use this information to detect illegal accesses. Larson and Austin propose a testing tool [23] to detect input related faults. This tool uses actual program execution using a test input, but enhances bug coverage by maintaining more information about the possible values of variables along the path followed by the test input. These techniques have the advantage that they can be used to detect more than just array out of bounds accesses, as is demonstrated in [23]. Moreover, the analysis is path sensitive since an actual program path is followed, and hence false alarm rates are low. However, the disadvantage is that the coverage of these tools is limited to the set of program paths examined.
BOON [29,30], like our tool, extracts a model from the source code - namely, these tools model strings as abstract data types and transform the buffer overrun detection problem into a range analysis problem. However, BOON does not employ precise pointer analysis algorithms. Moreover, the analysis was flow- and context- insensitive. Our tool builds on the seminal ideas introduced in BOON by using more precise pointer analysis algorithms, and enhances the program analysis to make it context-sensitive. Additionally, our tool employs algorithms based on linear programming for constraint resolution as opposed to the custom built range solver employed by BOON. Our tool also equips the user with several other static analysis algorithms such as static slicing, which enable the user to understand the reason behind the bug.
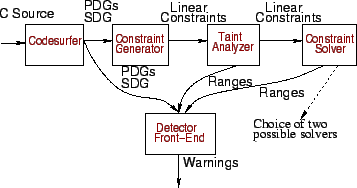
The constraint generator and the detector front-end are both developed as plug-ins to CodeSurfer. CodeSurfer is a code understanding tool that was originally designed to compute precise inter-procedural slices [20,21]. CodeSurfer builds a whole program representation that includes a system dependence graph (that is composed of program dependence graphs for each procedure), an inter-procedural control-flow graph, abstract syntax trees (ASTs) for program expressions, side-effect information, and points-to information. CodeSurfer presents the user with a GUI for exploring its internal program representations. The queries that CodeSurfer supports include forward and backward slicing from a program point, precise inter-procedural chopping between two program points, finding data and control dependence predecessors and successors from a program point, and examining the points-to set of a program variable. CodeSurfer presents the user with a listing of their source code that is ``hot'', i.e., the user can click on a program point in their code and ask any of the queries listed above.
CodeSurfer has two primary uses in our tool: (1) the constraint generator is a CodeSurfer plug-in that makes use of CodeSurfer's ASTs and pointer analysis (based on Andersen's analysis [6]). (2) the detector front-end is a CodeSurfer plug-in that uses CodeSurfer's GUI in order to display potential overruns. Information about potential overruns is linked to CodeSurfer's internal program representation, so that the user can make use of CodeSurfer's features, such as slicing, in order to examine potential overruns.
Constraint generation in our tool is similar to the approach proposed in BOON [30]. We also use points-to information returned by CodeSurfer, thus allowing for more precise constraints. Each pointer buf, to a character buffer, is modeled by four constraint variables, namely, buf!alloc!max and buf!alloc!min, which denote the maximum and minimum number of bytes allocated for the buffer, and buf!used!max and buf!used!min, which denote the maximum and minimum number of bytes used by the buffer. Each integer variable i is modeled by constraint variables i!max and i!min which represent the maximum and minimum value of i, respectively. Program statements that operate on character buffers or integer variables are modeled using linear constraints over constraint variables.
Our constraints model the program in a flow- and context insensitive manner, with the exception of library functions that manipulate character buffers. A flow-insensitive analysis ignores the order of statements, and a context-insensitive analysis does not differentiate between multiple call-sites to the same function. For a function call to a library function that manipulates strings (e.g., strcpy or strlen), we generate constraints that model the effect of the call; for these functions, the constraint model is context-sensitive. In Section 5, we will show how we extended the model to make the constraints context-sensitive for user defined functions as well.
Constraints are generated using a single pass over the program's statements.
There are four program statements that result in constraint generation: buffer
declarations, assignments, function calls, and return statements. A buffer
declaration such as char buf[![]() ] results in constraints
that indicate that buf is of size
] results in constraints
that indicate that buf is of size ![]() . A statement that
assigns into a character buffer (e.g., buf[i]='c')
results in constraints that reflect the effect of the assignment on
buf!used!max and buf!used!min. An assignment
to an integer i results in constraints on
i!max and i!min.
. A statement that
assigns into a character buffer (e.g., buf[i]='c')
results in constraints that reflect the effect of the assignment on
buf!used!max and buf!used!min. An assignment
to an integer i results in constraints on
i!max and i!min.
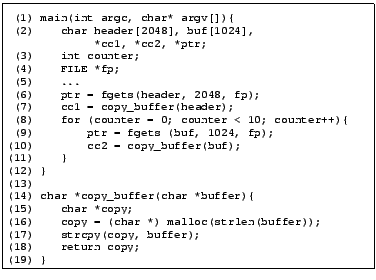
As mentioned above, a function call to a library function that manipulates string buffers is modeled by constraints that summarize the effect of the call. For example, the strcpy statement at line (18) in Figure 2 results in the following constraints:
For each user-defined function foo, there are constraint variables for foo's formal parameters that are integers or strings. If foo returns an integer or a string, then there are constraint variables (e.g., copy_buffer$return!used!max) for the function's return value. A call to a user-defined function is modeled with constraints for the passing of actual parameters and the assignment of the function's return value.
As in BOON, constraints are associated with pointers to character buffers rather than the character buffers themselves. This means that some aliasing among character buffers is not modeled in the constraints and false negatives may result. We chose to follow BOON in this regard because we are interested in improving precision by using a context sensitive program analysis (Section 5). Currently, context-sensitive pointer analysis does not scale well, and using a context-insensitive pointer analysis would undermine our aim of performing context-sensitive buffer overrun analysis.
However, we discovered that we could make use of pointer analysis to eliminate some false negatives. For instance, consider the statement ``strcpy(p->f, buf),'' where p could point to a structure s. The constraints generated for this statement would relate the constraint variables for s.f and buf. Moreover, we use the results of pointer analysis to handle arbitrary levels of dereferencing. Constraint generation also makes use of pointer information for integers.
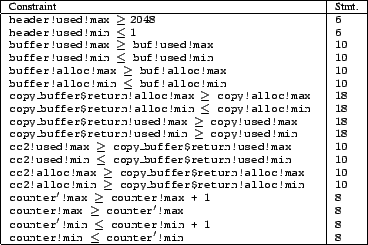
Figure 3 shows a few constraints for the program
in Figure 2, and the program statement
that generated them. Most of the constraints are self-explanatory, however a
few comments are in order:
![]() Since we do not model control flow, we ignore predicates during
constraint generation. Hence, in Figure 2,
the predicate counter
Since we do not model control flow, we ignore predicates during
constraint generation. Hence, in Figure 2,
the predicate counter ![]() in line (8)
was ignored.
in line (8)
was ignored.
![]() The statement counter++ is particularly interesting
when generating linear constraints. A linear constraint such as
counter!max
The statement counter++ is particularly interesting
when generating linear constraints. A linear constraint such as
counter!max ![]() counter!max +
counter!max + ![]() cannot be
interpreted by a linear program solver. Hence, we model this statement by
treating it as a pair of statements: counter
cannot be
interpreted by a linear program solver. Hence, we model this statement by
treating it as a pair of statements: counter![]() = counter
+
= counter
+ ![]() ; counter = counter
; counter = counter![]() . These two constraints capture the fact
that counter has been incremented by
. These two constraints capture the fact
that counter has been incremented by ![]() , and can be translated into constraints
that are acceptable to a linear program solver, although the
resulting linear program will be infeasible (Section
4).
, and can be translated into constraints
that are acceptable to a linear program solver, although the
resulting linear program will be infeasible (Section
4).
![]() A program variable that acquires its value from the environment or from user
input in an unguarded manner is considered unsafe - for instance, the statement
getenv("PATH"), which returns the search path, could return
an arbitrarily long string. To reflect the fact that the string can be arbitrarily
long, we generate constraints getenv$return!used!max
A program variable that acquires its value from the environment or from user
input in an unguarded manner is considered unsafe - for instance, the statement
getenv("PATH"), which returns the search path, could return
an arbitrarily long string. To reflect the fact that the string can be arbitrarily
long, we generate constraints getenv$return!used!max
![]() ,
getenv$return!used!min
,
getenv$return!used!min ![]() . Similarly, an integer variable
i accepted as user input gives rise to constraints
i!max
. Similarly, an integer variable
i accepted as user input gives rise to constraints
i!max
![]() and i!min
and i!min ![]() -
-![]()
The linear constraints then pass through a taint analysis module. The
main goal of the taint analysis module is to make the constraints amenable to
the solvers presented in Section 4. These solvers use
linear programming, which can work only with finite values, hence this requires
us to remove variables that can obtain infinite values. Section
4 will also demonstrate the importance of max variables having finite lower bounds and min variables
having finite upper bounds. Hence, taint analysis aims to:
![]() Identify and remove any variables that get an infinite value:
As mentioned in section 3.2, some constraint
variables var are associated with constraints of the form var
Identify and remove any variables that get an infinite value:
As mentioned in section 3.2, some constraint
variables var are associated with constraints of the form var
![]() or var
or var ![]() -
-![]() . Taint
analysis identifies constraint variables that can directly or indirectly
be set to
. Taint
analysis identifies constraint variables that can directly or indirectly
be set to
![]() and removes them from the set of constraints.
and removes them from the set of constraints.
![]() Identify and remove any uninitialized constraint variables:
The system of constraints is examined to see if all max
constraint variables have a finite lower bound, and all min
constraint variables have a finite upper bound; we refer to constraint
variables that do not satisfy this requirement as uninitialized.
Constraint variables may fail to satisfy the above requirement if either
the program variables that they correspond to have not been initialized in the
source code, or program statements that affect the value of the program variables
have not been captured by the constraint generator. The latter case may arise
when the constraint generator does not have a model for a library function that
affects the value of the program variable. It is important to realize that this
analysis is not meant to capture uninitialized program variables, but is
meant to capture uninitialized constraint variables.
Identify and remove any uninitialized constraint variables:
The system of constraints is examined to see if all max
constraint variables have a finite lower bound, and all min
constraint variables have a finite upper bound; we refer to constraint
variables that do not satisfy this requirement as uninitialized.
Constraint variables may fail to satisfy the above requirement if either
the program variables that they correspond to have not been initialized in the
source code, or program statements that affect the value of the program variables
have not been captured by the constraint generator. The latter case may arise
when the constraint generator does not have a model for a library function that
affects the value of the program variable. It is important to realize that this
analysis is not meant to capture uninitialized program variables, but is
meant to capture uninitialized constraint variables.
In the constraints obtained by the program in Figure 2, no variables will be removed by the taint analysis module, assuming that we modeled the library functions strlen, fgets and strcpy correctly. The taint analysis algorithm is presented in detail in [19].
We have developed a GUI front end that enables the end-user to ``surf'' the warnings - every warning is linked back to the source code line that it refers to. Moreover, the user can exploit the program slicing capabilities of CodeSurfer to verify real overruns.
This section describes two solvers based on linear programming that the tool
uses to solve the set of generated constraints. We chose to use linear
programming for several reasons:
![]() The use of linear programming allows us to model arbitrary linear
constraints. Hence, our solver automatically evolves to handle new
kinds of constraints. Other tools [29,30,33] use specialized solvers - generation of new kinds of
constraints will mean that these solvers have to be specially adapted
to deal with them.
The use of linear programming allows us to model arbitrary linear
constraints. Hence, our solver automatically evolves to handle new
kinds of constraints. Other tools [29,30,33] use specialized solvers - generation of new kinds of
constraints will mean that these solvers have to be specially adapted
to deal with them.
![]() Commercial implementations of linear program solvers are known to
scale efficiently to millions of constraints.
Commercial implementations of linear program solvers are known to
scale efficiently to millions of constraints.
![]() The use of a well developed theory helped us easily reason about the
correctness of our solvers.
The use of a well developed theory helped us easily reason about the
correctness of our solvers.
![]() Finally, we are currently working on the use of the dual of the
linear program for diagnostic information. In particular, we are
investigating how the dual linear program can be used to produce
a program path that leads to the statement that causes the overflow.
Such information is valuable since it tells the user of the tool
why there was an overrun.
Finally, we are currently working on the use of the dual of the
linear program for diagnostic information. In particular, we are
investigating how the dual linear program can be used to produce
a program path that leads to the statement that causes the overflow.
Such information is valuable since it tells the user of the tool
why there was an overrun.
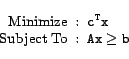
Linear programming is well studied in the literature, and there are well-known techniques to solve linear programs, Simplex [12,27] being the most popular of them. Other known techniques, such interior point methods [31] work in polynomial time. Commercially available solvers for solving linear programs, such as SoPlex [32] and CPLEX [25] implement these and related methods.
The set of constraints that we obtained after program analysis are linear constraints, hence we can formulate our problem as a linear program. Our goal is to obtain the values for buf!alloc!min, buf!alloc!max, buf!used!min and buf!used!max that yield the tightest possible ranges for the number of bytes allocated and used by the buffer pointed to by buf in such a way that all the constraints are satisfied. Formally, we are interested in finding the lowest possible values of buf!alloc!max and buf!used!max, and the highest possible values of buf!alloc!min and buf!used!min subject to the set of constraints. We can obtain the desired bounds for each buffer buf by solving four linear programs, each with the same constraints but with different objective functions:
| Minimize: buf!alloc!max |
| Maximize: buf!alloc!min |
| Minimize: buf!used!max |
| Maximize: buf!used!min |
Note that this objective function combines the constraint variables across all buffers. Since taint analysis ensures that all max variables have finite lower bounds and all min variables have finite upper bounds, we can solve just one linear program, and obtain the bounds for all buffers.
It must be noted that we are actually interested in obtaining integer values for buf!alloc!max, buf!used!max, buf!alloc!min and buf!used!min. The problem of finding integer solutions to a linear program is called Integer Linear Programming and is a well known NP-complete problem [12]. Our approach is thus an approximation to the real problem of finding integer solutions that satisfy the constraints.
In our formulation, if a linear program has an optimal solution, we can use that value as the buffer bound. None of the linear programs in our case can be unbounded, since the constraints have been examined by the taint analyzer to ensure that all max variables have finite lower bounds. We minimize for the max variables in the objective function, and since all the max variables have finite lower bounds, the lowest value that each max variable can obtain is also finite. Similarly, all min variables have finite upper bounds, and so when we maximize the min variables, the highest values that they could obtain are also finite. Hence taint analysis is an essential step to ensure that our approach works correctly.
However, when the linear program is infeasible, we cannot assign any finite
values to the variables to get a feasible solution. As a result, we cannot
obtain the values for the buffer bounds. In such a case, a safe option would be
to set all max variables to ![]() and min
variables to -
and min
variables to -![]() , but that information would be virtually useless to the
user of the tool because there would be too many false alarms. The linear
program may be infeasible due to a small subset of constraints; in such a
scenario, setting all variables to infinite values will be overly conservative.
For instance, the constraints in Figure 2 are
infeasible because of the constraints generated for the statement counter++.
, but that information would be virtually useless to the
user of the tool because there would be too many false alarms. The linear
program may be infeasible due to a small subset of constraints; in such a
scenario, setting all variables to infinite values will be overly conservative.
For instance, the constraints in Figure 2 are
infeasible because of the constraints generated for the statement counter++.
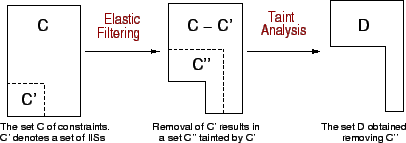
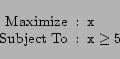
We have developed an approach in which we try to remove a ``small'' subset of the original set of constraints so that the resultant constraint system is feasible. In fact, the problem of ``correcting'' infeasible linear programs to make them feasible is a well studied problem in operations research. The approach is to identify Irreducibly Inconsistent Sets (called IIS) [9]. An IIS is a minimal set of inconsistent constraints, i.e., the constraints in the IIS together are infeasible, but any subset of constraints in the IIS form a feasible set. For instance, both the constraints in the linear program in Figure 5 constitute an IIS because the removal of any one of the two constraints makes the linear program feasible. There are several efficient algorithms available to detect IISs in a set of constraints. We used the Elastic Filtering algorithm [9]. The Elastic Filtering Algorithm takes as input a set of linear constraints and identifies an IIS in these constraints (if one exists). An infeasible linear program may have more than one IISs in it, and the elastic filtering algorithm is guaranteed to find at least one of these IISs. To produce a feasible linear program from an infeasible linear program, we may be required to run the elastic filtering algorithm several times; each run identifies and removes an IIS and produces a smaller linear program which can further be examined for presence of IISs.
Figure 6 pictorially shows our approach to
obtain a set of feasible linear constraints from a set of infeasible linear
constraints. We first examine the input set, depicted as ![]() , to find out if it
is feasible; if so, it does not contain IISs, and
, to find out if it
is feasible; if so, it does not contain IISs, and ![]() can be used as the set of
constraints in our linear program formulation. If the
can be used as the set of
constraints in our linear program formulation. If the ![]() turns out to be
infeasible, then it means that there is a subset of
turns out to be
infeasible, then it means that there is a subset of ![]() that forms one or more
IISs. This subset is depicted as
that forms one or more
IISs. This subset is depicted as ![]() in the figure. The elastic
filtering algorithm, over several runs, identifies and removes the subset
in the figure. The elastic
filtering algorithm, over several runs, identifies and removes the subset
![]() from the set of constraints. The resultant set
from the set of constraints. The resultant set
![]() is
feasible. We then set the values of the max and min
variables appearing in
is
feasible. We then set the values of the max and min
variables appearing in ![]() to
to ![]() and -
and -![]() respectively. We
do so because we cannot infer the values of these variables using linear
programming, and hence setting these variables to infinite values is a
conservative approach. These variables whose values are infinite may appear in
the set of constraints
respectively. We
do so because we cannot infer the values of these variables using linear
programming, and hence setting these variables to infinite values is a
conservative approach. These variables whose values are infinite may appear in
the set of constraints
![]() . The scenario is now similar to taint
analysis, where we had some constraint variables whose values were infinite,
and we had to identify and remove the constraint variables that were
``tainted'' by the infinite variables.
. The scenario is now similar to taint
analysis, where we had some constraint variables whose values were infinite,
and we had to identify and remove the constraint variables that were
``tainted'' by the infinite variables.
Therefore, we apply the taint analysis algorithm to identify the tainted
variables, and remove the constraints in which they appear. This step results
in further removal of constraints, which are depicted in the Figure
6 by a subset
![]() of
of
![]() . The set of constraints after removal of
. The set of constraints after removal of
![]() , denoted
as
, denoted
as ![]() in Figure 6, satisfies the property
that all max variables appearing in it have finite lower bounds,
and all min variables have finite upper bounds. Moreover,
in Figure 6, satisfies the property
that all max variables appearing in it have finite lower bounds,
and all min variables have finite upper bounds. Moreover, ![]() is
feasible, and will only yield optimal solutions when solved as a linear program
with the objective functions described earlier. Hence, we solve the linear
program using the set of constraints in
is
feasible, and will only yield optimal solutions when solved as a linear program
with the objective functions described earlier. Hence, we solve the linear
program using the set of constraints in ![]() . This algorithm is
presented in detail in [19].
. This algorithm is
presented in detail in [19].
We have implemented this approach by extending the commercially available package SoPlex [32]. SoPlex is a linear program solver; we extended it by adding IIS detection and taint analysis. In practice, linear program solvers work much faster when the constraints have been presolved. Presolving is a method by which constraints are simplified before being passed to the solver. Several such techniques are described in the literature [7]; we have incorporated some of them in our solver.
The constraint generation process described in Section 3 was context-insensitive. When we generated the constraints for a function, we considered each call-site as an assignment of the actual-in variables to the formal-in variables, and the return from the function as an assignment of the formal-out variables to the actual-out variables. As a result, we merged information across call-sites, thus making the analysis imprecise. In this section we describe two techniques to incorporate context sensitivity.
Constraint inlining is similar in spirit to inlining function bodies at call-sites. Observe that in the context-insensitive approach, we lost precision because we treated different call-sites to a function identically, i.e, by assigning the actual-in variables at each call-site to the same formal parameter.
Constraint inlining alleviates this problem by creating a fresh instance of the constraints of the called function at each call-site. At each call-site to a function, we produce the constraints for the called function with the local variables and formal parameters renamed uniquely for that call-site. This is illustrated in the example below, which shows some of the constraints for copy_buffer from Figure 2 specialized for the call-site at line (7):
| copy!alloc!max |
|
copy!used!max |
|
copy!used!min |
|
copy_buffer$return!used!max |
|
copy_buffer$return!used!min |
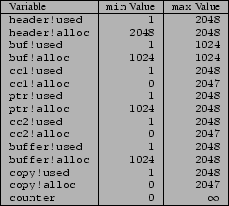
With this approach to constraint generation, we obtain the range [0..![]() ] and
[
] and
[![]() ..
..![]() ] for cc1!alloc and cc1!used respectively,
while cc2!alloc and cc2!used obtain [0..
] for cc1!alloc and cc1!used respectively,
while cc2!alloc and cc2!used obtain [0..![]() ] and
[
] and
[![]() ..
..![]() ] respectively, which is an improvement over the values reported in
Figure 4.
] respectively, which is an improvement over the values reported in
Figure 4.
Note that using the constraint inlining approach, we can obtain the value of a variable with a particular calling context (the calling context will be encoded implicitly in the renamed variable). However, this comes at a price - since we can have an exponential number of calling contexts, the constraint system will have a large number of variables, and as a result, a large number of constraints. Moreover, this approach cannot work with recursive function calls.
These drawbacks can be overcome through the use of summary information. In this approach to inter-procedural dataflow analysis, first suggested by Sharir and Pnueli [28], a ``summary'' is obtained for each function foo, and the summary information is used at each callsite to foo to ``simulate'' the effect of the call.
In our case, a function can be summarized by generating summary constraints, which summarize the effect of a function in terms of the constraint variables representing global variables and formal parameters of the function. This is equivalent to finding a projection of the constraints generated by the function on the global variables and the formal parameters of the function. This problem has several well-known solutions. In particular, if the function generates only difference constraints, then the problem of finding the summary constraints reduces to an instance of the all-pairs shortest path algorithm [12,19], for which several efficient algorithms are known. For more general kinds of constraints, the Fourier-Motzkin variable elimination algorithm [16] can be used.
Consider, for instance, constraints generated by copy_buffer. This function does not modify or use global variables, and hence we obtain the summary constraints (shown below) by projecting the constraints on the formal parameters of this function.
| copy_buffer$return!alloc!max |
|
copy_buffer$return!used!max |
|
copy_buffer$return!alloc!min |
|
copy_buffer$return!used!min |
To obtain context sensitivity, we use these constraints at each callsite to copy_buffer with the formal parameters appearing in the summary constraints replaced with the corresponding actuals. Constraints are generated at line (7) by replacing the constraint variables corresponding to buffer and copy_buffer$return in the summary constraints with the constraint variables corresponding to header and cc1 respectively. Similarly, the relationship between cc2 and buf at line (10) can be obtained by substituting them in place of copy_buffer$return and buffer respectively, in the summary constraints. Note that we must still retain the assignment of the actual variable to the formal-in parameter so that we can obtain the values of the constraint variables corresponding to the local variables of the called function.
This approach is more efficient than the constraint inlining approach since
it does not cause an increase in the number of constraint variables. However
it is also less precise than constraint inlining because of the same reason.
Observe that in constraint inlining the variables were renamed at each
callsite, thus enabling us to examine their values due to a particular calling
context. On the other hand, in the summary constraints approach the values of
the variables are merged across different calling contexts, thus leading to
loss of precision. For instance, consider the program in Figure
2. While the values for cc1!used,
cc1!alloc, cc2!used and cc2!alloc
are the same as obtained using constraint inlining, the values of copy!alloc and copy!used are [0..![]() ] and
[
] and
[![]() ..
..![]() ] respectively. This is because the values that these variables
obtained due to calls at line (7) and line (10)
are ``merged''. The constraint inlining approach returns the values
[0..
] respectively. This is because the values that these variables
obtained due to calls at line (7) and line (10)
are ``merged''. The constraint inlining approach returns the values
[0..![]() ] and [
] and [![]() ..
..![]() ] for copy!alloc and copy!used respectively due to the call at line (7),
and returns [0..
] for copy!alloc and copy!used respectively due to the call at line (7),
and returns [0..![]() ] and [
] and [![]() ..
..![]() ] due to the call at line
(10).
] due to the call at line
(10).
This approach is capable of handling recursive function calls, however for simplicity we do not attempt to summarize recursive function calls in our prototype implementation.
Our experiments were performed on a ![]() GHz Pentium-
GHz Pentium-![]() Xeon processor machine
with
Xeon processor machine
with ![]() GB RAM, running Debian GNU/Linux
GB RAM, running Debian GNU/Linux ![]() . We used
CodeSurfer-
. We used
CodeSurfer-![]() for our experiments, the gcc-3.2.1 compiler for
building the programs. CodeSurfer implements several pointer analysis
algorithms; in each case we performed the experiments with a field-sensitive
version of Andersen's analysis [6] that uses the
common-initial-prefix technique of Yong and Horwitz [34]
to deal with structure casts. We configured the tool to use the hierarchical
solver described in Section 4.3 for constraint
resolution (so the values obtained will be precise) and produce constraints in
a context-insensitive fashion. Section 6.4
discusses the effects of context-sensitive constraint generation.
for our experiments, the gcc-3.2.1 compiler for
building the programs. CodeSurfer implements several pointer analysis
algorithms; in each case we performed the experiments with a field-sensitive
version of Andersen's analysis [6] that uses the
common-initial-prefix technique of Yong and Horwitz [34]
to deal with structure casts. We configured the tool to use the hierarchical
solver described in Section 4.3 for constraint
resolution (so the values obtained will be precise) and produce constraints in
a context-insensitive fashion. Section 6.4
discusses the effects of context-sensitive constraint generation.
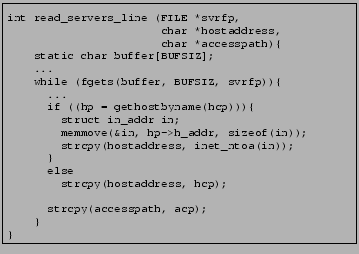
The tool reported a potential overrun on a buffer pointed to by
accesspath in the procedure read_servers_line in
the file rdservers.c, where as many as ![]() bytes could be copied
into the buffer for which up to
bytes could be copied
into the buffer for which up to ![]() bytes were allocated. Figure
7 shows the code snippet from
read_servers_line which is responsible for the overrun.
bytes were allocated. Figure
7 shows the code snippet from
read_servers_line which is responsible for the overrun.
The fgets statement may copy as many as ![]() (BUFSIZ) bytes into buffer, which is processed further in
this function. As a result of this processing, acp and hcp point to locations inside buffer. By an appropriate
choice of the contents of buffer, one could make acp or hcp point to a string buffer as long as
(BUFSIZ) bytes into buffer, which is processed further in
this function. As a result of this processing, acp and hcp point to locations inside buffer. By an appropriate
choice of the contents of buffer, one could make acp or hcp point to a string buffer as long as ![]() bytes,
which could result in an overflow on the buffer pointed to either by accesspath or hostname respectively.
bytes,
which could result in an overflow on the buffer pointed to either by accesspath or hostname respectively.
The procedure read_servers_line is called at several places in
the code. For instance, it is called in the main procedure in ftprestart.c where read_servers_line is called with
two local buffers, hostaddress and configdir, which
have been allocated ![]() bytes and
bytes and ![]() bytes respectively. This call reads the
contents of the file _PATH_FTPSERVERS, which typically has
privileged access. However, in non-standard and unusual configurations of the system,
_PATH_FTPSERVERS could be written to by a local user. As a
result, the buffers hostaddress and configdir can
overflow based on a carefully chosen input string, possibly leading to a local
exploit. The use of a strncpy or strlcpy statement
instead of the unsafe strcpy in read_servers_line
rectifies the problem.
bytes respectively. This call reads the
contents of the file _PATH_FTPSERVERS, which typically has
privileged access. However, in non-standard and unusual configurations of the system,
_PATH_FTPSERVERS could be written to by a local user. As a
result, the buffers hostaddress and configdir can
overflow based on a carefully chosen input string, possibly leading to a local
exploit. The use of a strncpy or strlcpy statement
instead of the unsafe strcpy in read_servers_line
rectifies the problem.
A few other new overruns which were detected by the tool were:
![]() An unchecked sprintf in main in the file ftprestart.c could result in
An unchecked sprintf in main in the file ftprestart.c could result in ![]() bytes being written into a local
buffer that was allocated
bytes being written into a local
buffer that was allocated ![]() bytes.
bytes.
![]() Another unchecked sprintf in main in the file
ftprestart.c could result in
Another unchecked sprintf in main in the file
ftprestart.c could result in ![]() bytes being written into a
local buffer that was allocated
bytes being written into a
local buffer that was allocated ![]() bytes.
bytes.
![]() An unchecked strcpy in main in the file ftprestart.c could result in
An unchecked strcpy in main in the file ftprestart.c could result in ![]() bytes being written into a local
buffer that was allocated
bytes being written into a local
buffer that was allocated ![]() bytes.
bytes.
In each of the above cases, a carefully chosen string in the file _PATH_FTPACCESS can be used to cause the overrun. As before, _PATH_FTPACCESS typically has privileged access, but could be written to by a local user in non-standard configurations. We contacted the wu-ftpd developers, and they have acknowledged the presence of these bugs in their code, and are in the process of fixing the bugs (at the time of writing this paper).
| dst |
|
dst!used!max |
|
dst |
|
dst!used!min |
sendmail-8.7.6 has about ![]() K lines of code; when analyzed by our
tool, it produced
K lines of code; when analyzed by our
tool, it produced ![]() warnings. Due to the large number of warnings, we focused
on scanning the warnings to detect some known overruns.
warnings. Due to the large number of warnings, we focused
on scanning the warnings to detect some known overruns.
Wagner et al. use BOON to report an off-by-one bug [30]
in sendmail-8.9.3 where as many as ![]() bytes, returned by a function
queuename, could be written into a
bytes, returned by a function
queuename, could be written into a ![]() byte array dfname.
Our tool identified four possible program points in sendmail-8.7.6
where the return value from queuename is copied using
strcpy statements into buffers which are allocated
byte array dfname.
Our tool identified four possible program points in sendmail-8.7.6
where the return value from queuename is copied using
strcpy statements into buffers which are allocated ![]() bytes. As in
[30], our tool reported that the return value from
queuename could be up to
bytes. As in
[30], our tool reported that the return value from
queuename could be up to ![]() bytes long, and further manual
analysis was required to decipher that this was in fact an off-by-one bug.
Another minor off-by-one bug was reported by the tool where the programmer
mistakenly allocated only
bytes long, and further manual
analysis was required to decipher that this was in fact an off-by-one bug.
Another minor off-by-one bug was reported by the tool where the programmer
mistakenly allocated only ![]() bytes for the buffer delimbuf which
stored "
bytes for the buffer delimbuf which
stored "
![]() n
n
![]() t ", which is
t ", which is ![]() bytes long
including the end of string character.
bytes long
including the end of string character.
One of these vulnerabilities is on a function crackaddr in the file headers.c, which parses an incoming e-mail address string. This function stores the address string in a local static buffer called buf that is declared to be MAXNAME + 1 bytes long, and performs several boundary condition checks to see that buf does not overflow. However, the condition that handles the angle brackets (<>) in the From address string is imprecise, thus leading to the overflow [5].
Our tool reported that bp, a pointer to the buffer buf in the function had bp!alloc!max = +![]() and
bp!used!max = +
and
bp!used!max = +![]() , thus raising an warning. However, the
reason that bp!alloc!max and bp!used!max were set to
+
, thus raising an warning. However, the
reason that bp!alloc!max and bp!used!max were set to
+![]() was because of several pointer arithmetic statements in the body of
the function. In particular, the statement bp- resulted in bp!alloc!max = +
was because of several pointer arithmetic statements in the body of
the function. In particular, the statement bp- resulted in bp!alloc!max = +![]() and bp!used!max = +
and bp!used!max = +![]() .
Hence, this warning would have existed even if the boundary condition checks
were correct.
.
Hence, this warning would have existed even if the boundary condition checks
were correct.
We note that this bug is hard to track precisely in a flow-insensitive analysis. Moreover, we have discovered that the use of control dependence information, which associates each statement with the predicate that decides whether the statement will be executed, is crucial to detecting such overruns reliably. We are working towards enhancing our infrastructure to support these features.
Table 1 contains representative numbers from our experiments with wu-ftpd-2.6.2 and sendmail-8.7.6. All timings were obtained using the UNIX time command. CODESURFER denotes the time taken by CodeSurfer to analyze the program, GENERATOR denotes the time taken for constraint generation, while TAINT denotes the time taken for taint analysis. The constraints produced can be resolved in one of two ways; the rows LPSOLVE and HIERSOLVE report the time taken by the IIS detection based approach and the hierarchical solves approach respectively (Section 4). The number of constraints output by the constraint generator is reported in the row PRE-TAINT, while POST-TAINT denotes the number of constraints after taint-analysis.
As noted earlier, the IIS detection based approach is more efficient, but is
not mathematically precise, whereas the hierarchical solver is mathematically
precise. We however found that the solution produced by the IIS detection based
approach is a good approximation to the solution obtained by the hierarchical
solver. In case of wu-ftpd-2.6.2 fewer than ![]() % of the
constraint variables, and in the case of sendmail-8.7.6 fewer
than
% of the
constraint variables, and in the case of sendmail-8.7.6 fewer
than ![]() % of the constraint variables obtained imprecise values when we used
the IIS detection based approach. We also found that this imprecision did not
significantly affect the number of warnings - in case of wu-ftpd-2.6.2 and sendmail-8.7.6 the IIS based approach
resulted in
% of the constraint variables obtained imprecise values when we used
the IIS detection based approach. We also found that this imprecision did not
significantly affect the number of warnings - in case of wu-ftpd-2.6.2 and sendmail-8.7.6 the IIS based approach
resulted in ![]() and
and ![]() more warnings respectively (these warnings were false alarms),
which shows that in practice we can use the faster IIS detection based approach
with little loss of precision.
more warnings respectively (these warnings were false alarms),
which shows that in practice we can use the faster IIS detection based approach
with little loss of precision.
The context-insensitive analysis on wuftpd-2.6.2 yields values
for ![]() range variables. Using the summary constraints approach, we found that
range variables. Using the summary constraints approach, we found that
![]() of these range variables obtained more precise values. Note that in this
approach the number of constraint variables (and hence the number of range
variables) is the same as in the context-insensitive analysis. However, the
number of constraints may change, and we observed a
of these range variables obtained more precise values. Note that in this
approach the number of constraint variables (and hence the number of range
variables) is the same as in the context-insensitive analysis. However, the
number of constraints may change, and we observed a ![]() increase in the
number of constraints. This change can be attributed to the fact that
summarization introduces a some constraints (the summaries), and removes some
constraints (the old call-site assignment constraints).
increase in the
number of constraints. This change can be attributed to the fact that
summarization introduces a some constraints (the summaries), and removes some
constraints (the old call-site assignment constraints).
The constraint inlining approach, on the other hand, leads to a ![]() increase in the number of constraints, and a
increase in the number of constraints, and a ![]() increase in the
number of constraint variables (and hence the number of range variables).
This can be attributed to the fact that the inlining based approach specializes
the set of constraints at each callsite. In particular, we observed that the
increase in the
number of constraint variables (and hence the number of range variables).
This can be attributed to the fact that the inlining based approach specializes
the set of constraints at each callsite. In particular, we observed that the
![]() range variables from the context-insensitive analysis were specialized to
range variables from the context-insensitive analysis were specialized to
![]() range variables based on calling context. We can count the number of range
variables that obtained more precise values in two possible ways:
range variables based on calling context. We can count the number of range
variables that obtained more precise values in two possible ways:
![]() Out of
Out of ![]() specialized range variables,
specialized range variables, ![]() range variables
obtained more precise values than the corresponding unspecialized range
variables.
range variables
obtained more precise values than the corresponding unspecialized range
variables.
![]() Out of
Out of ![]() unspecialized range variables,
unspecialized range variables, ![]() range variables
had obtained more precise values in at least one calling context.
range variables
had obtained more precise values in at least one calling context.
As noted earlier, the constraint inlining approach returns more precise information
than the summary constraints based approach. To take a concrete example, we
consider the program variable msgcode (an integer), which is the
formal parameter of a function pr_mesg in the file access.c in wu-ftpd-2.6.2. The function pr_mesg is called from several places in the code with different values for
the parameter msgcode. The summary constraints approach results
in the value [![]() ..
..![]() ] for the range variable corresponding to msgcode. Constraint inlining refines these ranges -
for instance, it is able to infer that pr_mesg is always called
with the value
] for the range variable corresponding to msgcode. Constraint inlining refines these ranges -
for instance, it is able to infer that pr_mesg is always called
with the value ![]() from the function pass in the file ftpd.c.
from the function pass in the file ftpd.c.
To observe the benefits of pointer analysis we generated constraints with the
pointer analysis algorithms turned off. Since fewer constraints will be
generated, we can expect to see fewer warnings; in the absence of these
warnings, false negatives may result. We observed a concrete case of this in
the case of sendmail-8.7.6. When we generated constraints without
including the results of the pointer analysis algorithms, the tool output ![]() warnings (as opposed to
warnings (as opposed to ![]() warnings). However, this method resulted in the
warning on the array dfname being suppressed, so the tool
missed the off-by-one bug that we described earlier. A closer look at the
procedure queuename revealed that in the absence of
points-to facts, the tool failed to generate constraints for a statement:
warnings). However, this method resulted in the
warning on the array dfname being suppressed, so the tool
missed the off-by-one bug that we described earlier. A closer look at the
procedure queuename revealed that in the absence of
points-to facts, the tool failed to generate constraints for a statement:
snprintf(buf, sizeof buf, "%cf%s", type, e![]() e_id)
e_id)
in the body of queuename since points to facts for the variable
e, which is a pointer to a structure, were not generated.
We note that BOON [30] identified this off-by-one bug because of a simple assumption made to model the effect of pointers, i.e., BOON assumes that any pointer to a structure of type T can point to all structures of type T. While this technique can be effective at discovering bugs, the lack of precise points-to information will lead to a larger number of false alarms.
First, the flow insensitivity of the analysis meant that we would have several false alarms. Through the use of slicing we were able to weed out the false alarms, nevertheless it was a manual and often painstaking procedure. Moreover, the benefits observed by adding context-sensitivity were somewhat limited because of the flow insensitivity of the analysis. By transitioning to a Static Single Assignment (SSA) representation [15] of the program, we can add a limited form of flow sensitivity to the program. However, the SSA representation will result in a large number of constraint variables. Fortunately, we have observed that the solvers readily scale to large linear programs with several thousand variables.
Second, by modeling constraints in terms of pointers to buffers rather than buffers, we can miss overruns, thus leading to false negatives [30]. However, the reason we did so was because the pointer analysis algorithms themselves were flow- and context-insensitive, and generating constraints in terms of buffers would have resulted in a large number of constraints and consequently a large number of false alarms. By transitioning to ``better'' pointer analysis algorithms we can model constraints in terms of buffers themselves, thus eliminating the false negatives.
Acknowledgments. We would like to thank the members of
the Wisconsin Safety Analyzer research group, Michael Ferris, Aditya Rao
and the anonymous reviewers for their suggestions.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -local_icons ccs2003_html.tex
The translation was initiated by Vinod Ganapathy on 2005-07-14