

Sumit K Mandal(Google Scholar | LinkedIn)
Assistant Professor
Department of Computer Science and Automation
Indian Institute of Science
Bengaluru 560012, India
Overview of my research work (Google Scholar)
Networks-on-chip (NoCs) have become the standard for interconnect solutions in industrial designs ranging from client CPUs to many-core chip-multiprocessors. Long NoC simulations increase the execution time of evaluation frameworks, which are already notoriously slow, and prohibit design-space exploration. Existing analytical NoC models, which assume fair arbitration, cannot replace these simulations since industrial NoCs typically employ priority schedulers and multiple priority classes. Moreover, NoCs used in commercial many-core processors incorporate deflection routing and typically experience bursty traffic due to application workloads. There exists no NoC performance model which can handle all these properties of industrial NoCs. To address this limitation, we propose a systematic approach to construct priority-aware analytical performance models considering bursty traffic and deflection routing using micro-architecture specifications and input traffic. We introduce novel transformations along with an algorithm that iteratively applies these transformations to decompose the queuing system. Experimental evaluations using real architectures and applications show high accuracy of 97% and up to 2.5x speed-up in full-system simulation.
Apart from Systems-on-Chip (SoCs), data communication plays a significant role in overall performance for hardware accelerators of Deep Neural Networks (DNNs). For example, crossbar-based in-memory computing significantly increases on-chip communication volume since the weights and activations are on-chip. Our experiments show that up to 90% of the total inference latency of a DNN hardware is spent on on-chip communication when a bus-based network is used. To reduce communication latency, we propose a methodology to generate an NoC architecture and a scheduling technique customized for different DNNs. We prove mathematically that the developed NoC architecture and corresponding schedules achieve the minimum possible communication latency for a given DNN. Experimental evaluations on a wide range of DNNs show that the proposed NoC architecture enables 20%-80% reduction in communication latency with respect to state-of-the-art interconnect solutions.
A report of my research is here.
Detailed description of my research work
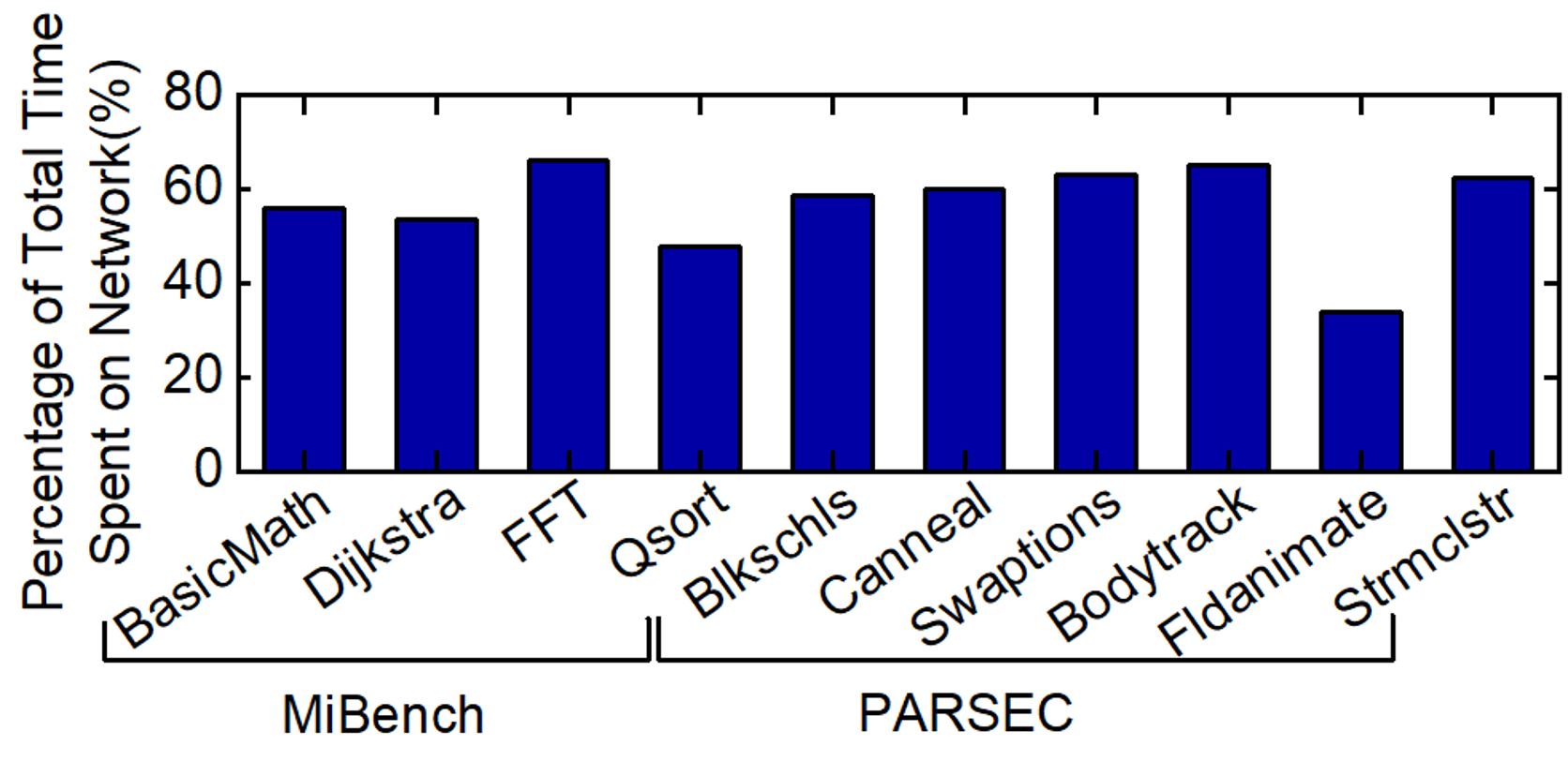
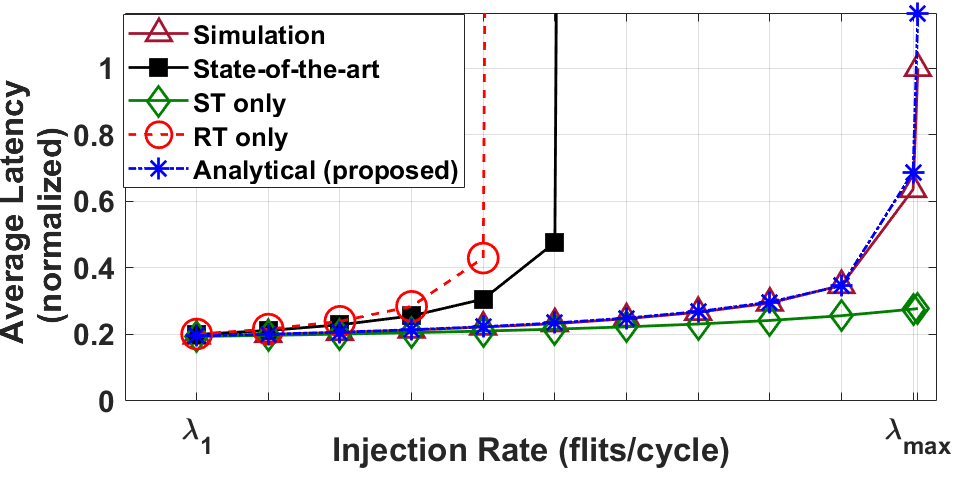
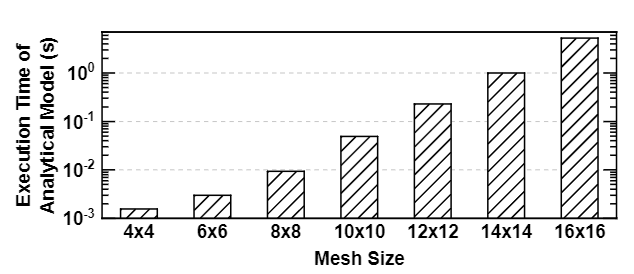
Modern design methodologies in industries involve thorough power, performance, and area evaluations before the architectural decisions are frozen. These pre-silicon evaluations are vital for detecting functional bugs and power-performance violations, since post-silicon fixes are costly, if feasible at all. Therefore, a significant amount of resources are dedicated to pre-silicon evaluation using virtual platforms or full-system simulators. NoC simulations play a critical role in these evaluations, as NoCs have become the standard interconnect solution in many core chip-multiprocessors (CMPs), client CPUs, and mobile systems-on-chip. NoC simulations take up a significant portion of the total simulation time, which is already limiting the scope of pre-silicon evaluation (e.g., simulating even a few seconds of applications can take days). For example, the bar graph above shows that 40%-70% of total simulation time is spent on the network itself when performing full-system simulation using gem5. This work presents a novel NoC performance analysis technique that considers traffic classes with different priorities. We propose a two-step approach that consists of an analysis technique followed by an iterative algorithm. The first step establishes that priority-based NoCs can be decomposed into separate queues using traffic splits of two types. To this end we propose two novel network transformations: structural transformation (ST) and service rate transformation (RT). The second step involves a novel iterative algorithm that composes an end-to-end latency model for the queuing network of a given NoC topology and input traffic pattern. The proposed approach is evaluated thoroughly using both 2D mesh and ring architectures used in industrial NoCs. It achieves 97% accuracy (figure below in the left) with respect to cycle-accurate simulations for realistic architectures and applications. The analytical model performs performance estimation of a 16x16 mesh in only 5 seconds (figure below in the right). This is the first analytical model for NoC which considers priority-aware NoC with deflection routing under bursty traffic.
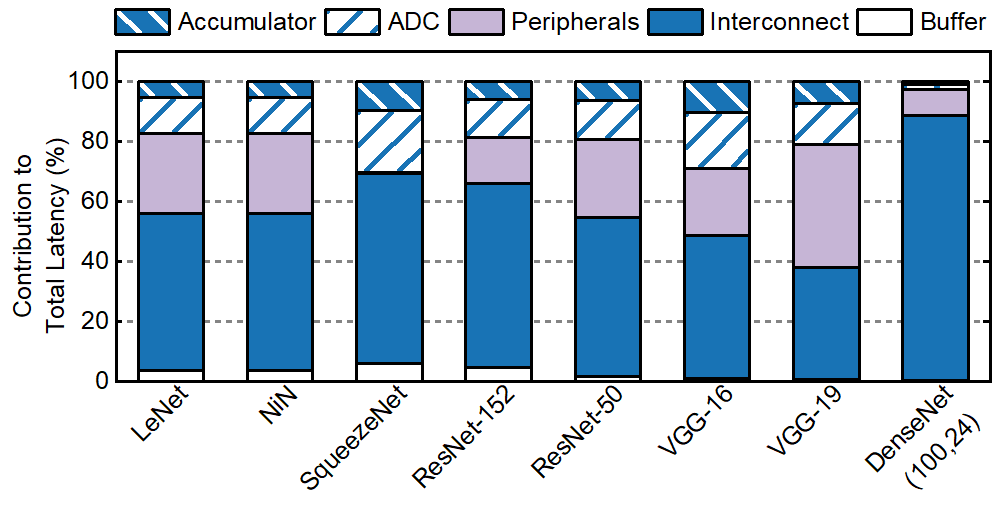
In recent years, deep neural networks (DNNs) have shown tremendous success in recognition and detection tasks such as image processing, health monitoring, and language processing. Higher accuracy in DNNs is achieved by using larger and more complex models. However, such models require a large number of weights, and consequently, traditional DNN hardware accelerators require a large number of memory accesses to fetch the weights from off-chip memory, leading to a large number of off-chip memory accesses lead to higher latency and energy consumption. On average, a single off-chip memory access consumes 1,000x the energy of a single computation. In-Memory Computing (IMC) techniques reduce memory access related latency and energy consumption through the integration of computation with memory accesses. A prime example is the crossbar-based IMC architecture which provides a significant throughput boost for DNN acceleration. At the same time, crossbar-based in-memory computing dramatically increases the volume of on-chip communication, when all weights and activations are stored on-chip. 40%-90% of the inference latency is spent on communication as shown in the figure above. In this work, we first propose an optimization technique to determine the optimal number of NoC routers required for each layer of the DNN. Next, we propose a methodology to generate a latency-optimized NoC architecture along with a scheduling technique customized for different DNNs. We prove, through induction, that the proposed NoC architecture achieves minimum possible communication latency using the minimum number of links between the routers. These two techniques together generate a custom NoC for IMC acceleration of a given DNN. We show that the proposed custom IMC architecture achieves 20%-80% improvement in overall communication latency and 5%-25% reduction in end-to-end inference latency with respect to state-of-the-art NoC based IMC architectures.
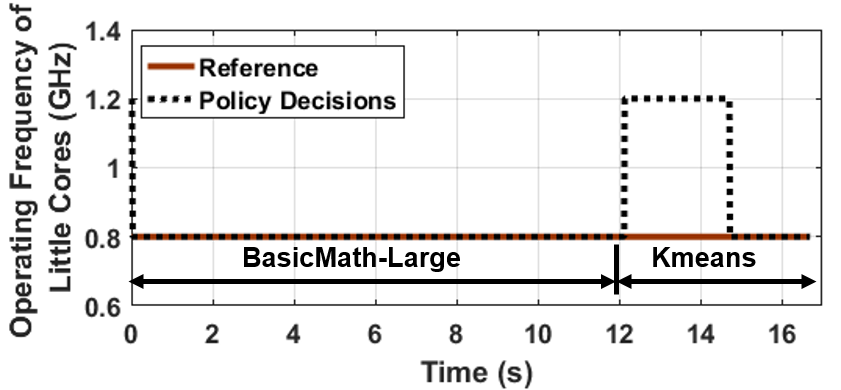
Over a billion people use various types of electronic devices including mobile phones, tablets, and personal computers. As the processing and sensing capabilities of these devices expand, we see exponential growth in the number and types of applications. Common examples include graphics-intensive games, communication-intensive social media apps, health monitoring, and traditional compute-intensive applications. Delivering the required performance on-demand and maximizing the battery life are two common goals independent of the application. However, the runtime configurations to achieve these goals can vary dramatically for different application scenarios (as shown in the plot above). For example, high-performance CPU cores (e.g., big cores) are preferred over low-power cores while running compute-intensive applications. Furthermore, the voltage and frequency levels should be controlled optimally at runtime, since the highest (i.e., most power-hungry) levels are not needed continuously. Determining the optimal SoC configuration at runtime is challenging for huge design space and potenitially unlimited number of new applications.In this work, we propose a novel online imitation learning (Online-IL) approach to learn optimal policies for new applications at runtime. The Online-IL approach leverages an offline control algorithm, constructed at design-time, as the initial policy to effectively bootstrap the learning process. This policy may not perform well on new applications seen at runtime. Hence, the proposed Online-IL approach synergistically combines the benefits of power/performance models and machine learning techniques. The power/performance models provide strong supervision via low-overhead and accurate evaluation of candidate configurations. Our machine learning techniques leverage this supervision to efficiently adapt the policy to new applications. Experimental evaluations on Odroid-XU3 board show that offline policies achieve almost 100% accuracy with respect to a golden reference while running applications from the training set. However, they perform poorly under new applications seen at runtime. Our proposed online-IL methodology adapts the offline policy online to new applications within a few seconds.